#create vectors of respondents' names;
vec_respondents_oevp <- c(
"Kurz", "Blümel", "Bonelli", "Mei-Pochtler",
"Spiegelfeld-Quester", "Nehammer", "Purkart", "Sobotka")
vec_respondents_oevp_or <- paste(vec_respondents_oevp, collapse="|")
vec_respondents_fpoe <- c("Strache", "Gudenus", "Hofer", "Kickl")
vec_respondents_fpoe_or <- paste(vec_respondents_fpoe, collapse="|")
vec_respondents_gruene <- c("Zadic")
vec_respondents_gruene_or <- paste(vec_respondents_gruene, collapse="|")
vec_respondents_spoe <- c("Christian Kern")
vec_respondents_spoe_or <- paste(vec_respondents_spoe, collapse="|")
vec_respondents_all_or <- paste(vec_respondents_oevp_or, vec_respondents_fpoe_or,
vec_respondents_gruene_or, vec_respondents_spoe_or,
sep="|")
library(cowplot)
library(rlang)
library(ggtext)
element_textbox_highlight <- function(...,
hi.labels = NULL, hi.fill = NULL,
hi.col = NULL, hi.box.col = NULL,
hi.labels2 = NULL, hi.fill2 = NULL,
hi.col2 = NULL, hi.box.col2 = NULL) {
structure(
c(element_textbox(...),
list(hi.labels = hi.labels, hi.fill = hi.fill, hi.col = hi.col, hi.box.col = hi.box.col,
hi.labels2 = hi.labels2, hi.fill2 = hi.fill2, hi.col2 = hi.col2, hi.box.col2 = hi.box.col2)
),
class = c("element_textbox_highlight", "element_textbox", "element_text", "element",
"element_textbox_highlight", "element_textbox", "element_text", "element")
)
}
element_grob.element_textbox_highlight <- function(element, label = "", ...) {
if (label %in% element$hi.labels) {
element$fill <- element$hi.fill %||% element$fill
element$colour <- element$hi.col %||% element$colour
element$box.colour <- element$hi.box.col %||% element$box.colour
}
if (label %in% element$hi.labels2) {
element$fill <- element$hi.fill2 %||% element$fill
element$colour <- element$hi.col2 %||% element$colour
element$box.colour <- element$hi.box.col2 %||% element$box.colour
}
NextMethod()
}
library(lemon)
df_data %>%
filter(str_detect(respondent, regex(vec_respondents_all_or))) %>%
filter(speaker_position == "Auskunftsperson") %>%
filter(!is.na(respondent_questioner_party)) %>%
mutate(facet_label=glue::glue("{speaker_name} ({session_no})")) %>%
ggplot() +
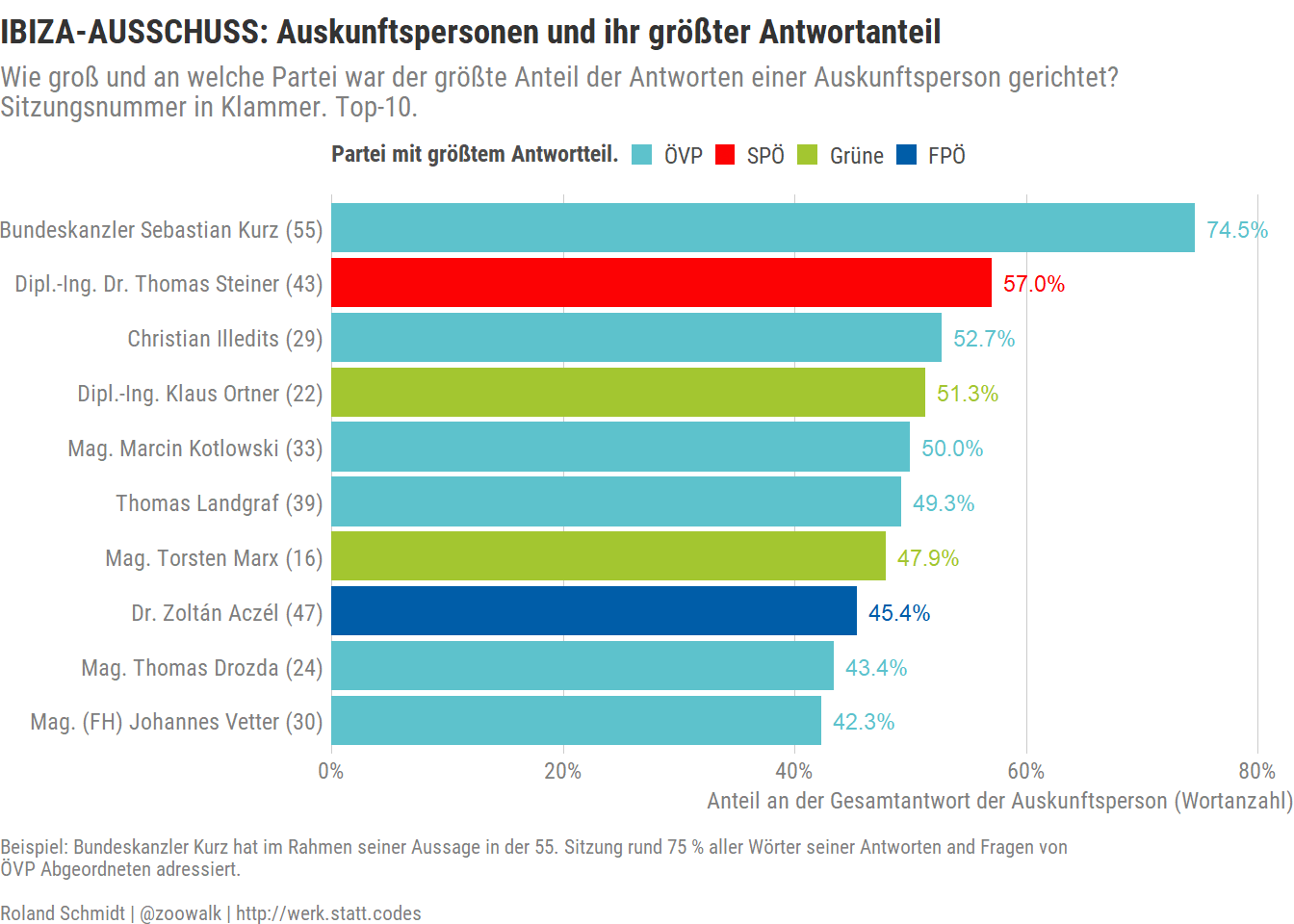
labs(title="IBIZA-AUSSCHUSS: Länge der Antworten von Auskunftspersonen \nper Parteimitgliedschaft der fragenden Abgeordneten",
subtitle="Ausgewählte Auskunftspersonen. Sitzungsnummer in Klammer.",
caption=c("Jeder Punkt stellt eine Antwort/Wortmeldung der Auskunftsperson dar. Die Position auf der x-Achse gibt an welcher Partei der/die \nAbgeordnete angehört, der/die zuvor eine Frage gestellt hatte bzw. an den/die die Antwort der Auskunftsperson gerichtet war. Die Position auf der y-Achse zeigt die Länge der Antwort der Auskunftsperson als Anzahl an Wörtern an.\n\nRoland Schmidt | @zoowalk | http://werk.statt.codes"),
# y="Länge der Antwort (Anzahl v. Wörtern)",
x="Parteizugehörigkeit der/s Abgeordneten")+
geom_jitter(aes(
x = respondent_questioner_party,
y = text_length,
color=respondent_questioner_party),
size=0.5
)+
scale_color_manual(values=vec_party_col)+
scale_y_continuous(expand=expansion(mult=c(0.01, 0.1)),
breaks=c(0,500, 1000, 1400),
labels=c("0", "500", "1000", "1400 Wörter"))+
lemon::facet_rep_wrap(~facet_label,
ncol=3,
repeat.tick.labels = "x",
labeller=label_wrap_gen(width = 30))+
theme_post()+
theme(
# strip.text = element_text(color="grey20"),
axis.text.x=element_text(size=7),
axis.title.x=element_text(hjust=0,
size=7),
axis.text.y=element_text(size=7),
panel.spacing.x = unit(0, units="cm"),
legend.position = "none",
axis.title.y=element_blank(),
panel.grid.major.x=element_blank(),
strip.text = element_textbox_highlight(
size = 8,
# unnamed set (all facet windows except named sets below)
color = "black",
fill = "white",
box.color = "white",
halign = 0,
valign=0.5,
linetype = 1,
# r = unit(5, "pt"),
# height=unit(1, "cm"),
width = unit(1, "npc"), #expands text box to full width of facet
#padding = margin(2, 0, 1, 0),
#margin = margin(3, 3, 3, 3),
# this is new relative to element_textbox():
# first named set
hi.labels = c("Sebastian Kurz (55)", "Herbert Kickl (41)"),
hi.fill = "black",
hi.box.col = "black", #line around box
hi.col = "white"))