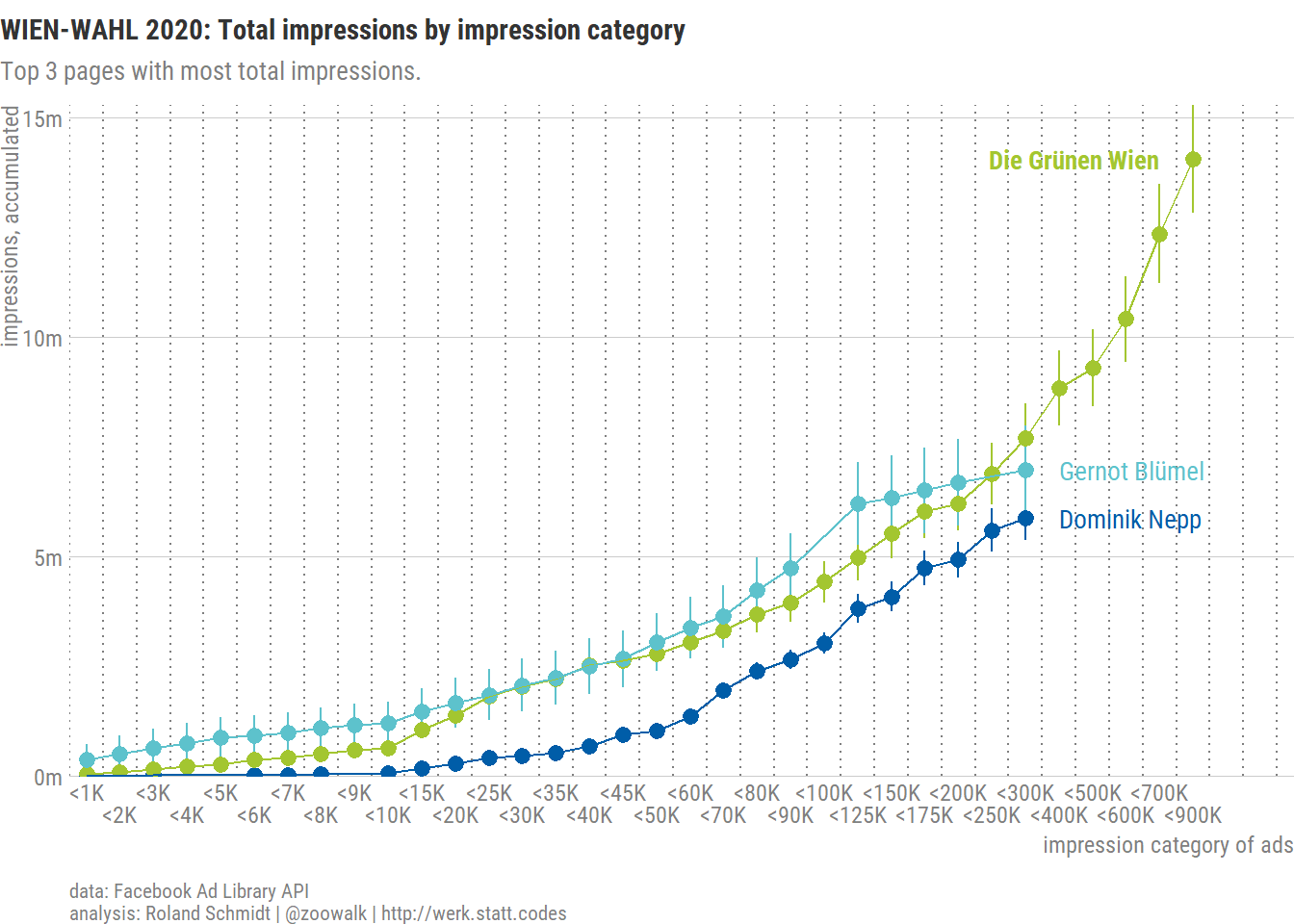
# Number and values of ads
df_party<- df_ads_wide %>%
group_by(party) %>%
summarise(ads_n=n(),
across(.cols=contains("spend_") & where(is.numeric),
.fns=sum)) %>%
select(party, ads_n, spend_lower_bound_rev, spend_mid, spend_upper_bound) %>%
ungroup() %>%
arrange(-ads_n)
#nested pages df
df_pages <- df_ads_wide %>%
group_by(party, page_name) %>%
summarise(ads_n=n(),
across(.cols=contains("spend_") & where(is.numeric),
.fns=sum)) %>%
select(party, page_name, ads_n, spend_lower_bound_rev, spend_mid, spend_upper_bound) %>%
ungroup() %>%
arrange(-ads_n)
#nested funding entities
df_funding <- df_ads_wide %>%
group_by(party, page_name, funding_entity) %>%
summarise(ads_n=n(),
across(.cols=contains("spend_") & where(is.numeric),
.fns=sum)) %>%
select(party, page_name, funding_entity, ads_n, spend_lower_bound_rev, spend_mid, spend_upper_bound) %>%
ungroup() %>%
arrange(-ads_n)
#funding table
rt_page_funding <- reactable(df_pages,
details=function(index) {
funding_data <- df_funding[df_funding$page_name==df_pages$page_name[index],]
htmltools::div(style = "padding: 16px",
reactable(funding_data,
columns=list(
party=colDef(show=F),
page_name=colDef(show=F)),
sortable = T,
filterable = T,
outlined = TRUE))})
orange_pal <- function(x) rgb(colorRamp(c(plot_bg_color, "#ff9500"))(x), maxColorValue = 255)
blue_pal <- function(x) rgb(colorRamp(c(plot_bg_color, "#0C6D82"))(x), maxColorValue = 255)
#assemble table
rt_party_pages <- reactable(df_party,
columnGroups = list(
colGroup(name="spending",
columns=c("spend_lower_bound_rev",
"spend_mid",
"spend_upper_bound"))
),
columns=list(
party=colDef(name="party"),
ads_n=colDef(name="number of ads",
format=colFormat(separators = T),
style=function(value){
normalized <- (value-min(df_party$ads_n))/(max(df_party$ads_n)-min(df_party$ads_n))
color <- orange_pal(normalized)
list(background=color)
}),
spend_lower_bound_rev=colDef(name="min",
format=colFormat(separators = T,
digits=0)),
spend_mid=colDef(name="mid",
format=colFormat(separators = T,
digits=0),
style=function(value){
normalized <- (value-min(df_party$spend_mid))/(max(df_party$spend_mid)-min(df_party$spend_mid))
color <-blue_pal(normalized)
list(background=color)
}),
spend_upper_bound=colDef(name="max",
format=colFormat(separators = T,
digits=0))),
sortable = T,
filterable = F,
outlined = TRUE,
theme=reactableTheme(
backgroundColor = plot_bg_color,
filterInputStyle = list(
color="green",
backgroundColor = plot_bg_color)
),
details = function(index) {
page_data <- df_pages[df_pages$party == df_party$party[index], ]
htmltools::div(style = "padding: 16px;",
reactable(page_data,
columns=list(
party=colDef(show=F),
page_name=colDef(name="fb page"),
ads_n=colDef(name="number of ads",
format=colFormat(separators = T)),
spend_lower_bound_rev=colDef(name="min",
format=colFormat(separators = T)),
spend_mid=colDef(name="mid",
format=colFormat(separators = T)),
spend_upper_bound=colDef(name="max",
format=colFormat(separators = T))),
theme=reactableTheme(backgroundColor = plot_bg_color,
filterInputStyle = list(
color="green",
backgroundColor = plot_bg_color) ),
sortable = T,
style="margin-left:60px;",
fullWidth = T,
filterable = T,
borderless = T,
outlined = TRUE,
details = function(index) {
funding_data <- df_funding[df_funding$page_name==page_data$page_name[index]&
df_funding$party == page_data$party[index],]
htmltools::div(style = "padding: 2px;",
reactable(funding_data,
columns=list(
party=colDef(show=F),
page_name=colDef(show=F),
funding_entity=colDef(name="funding entity"),
ads_n=colDef(name="number of ads"),
spend_lower_bound_rev=colDef(name="min"),
spend_mid=colDef(name="mid"),
spend_upper_bound=colDef(name="max")),
theme=reactablefmtr::nytimes(),
sortable = T,
borderless = T,
style="margin-left:60px",
filterable = F,
outlined = TRUE))}
)
)
}
)