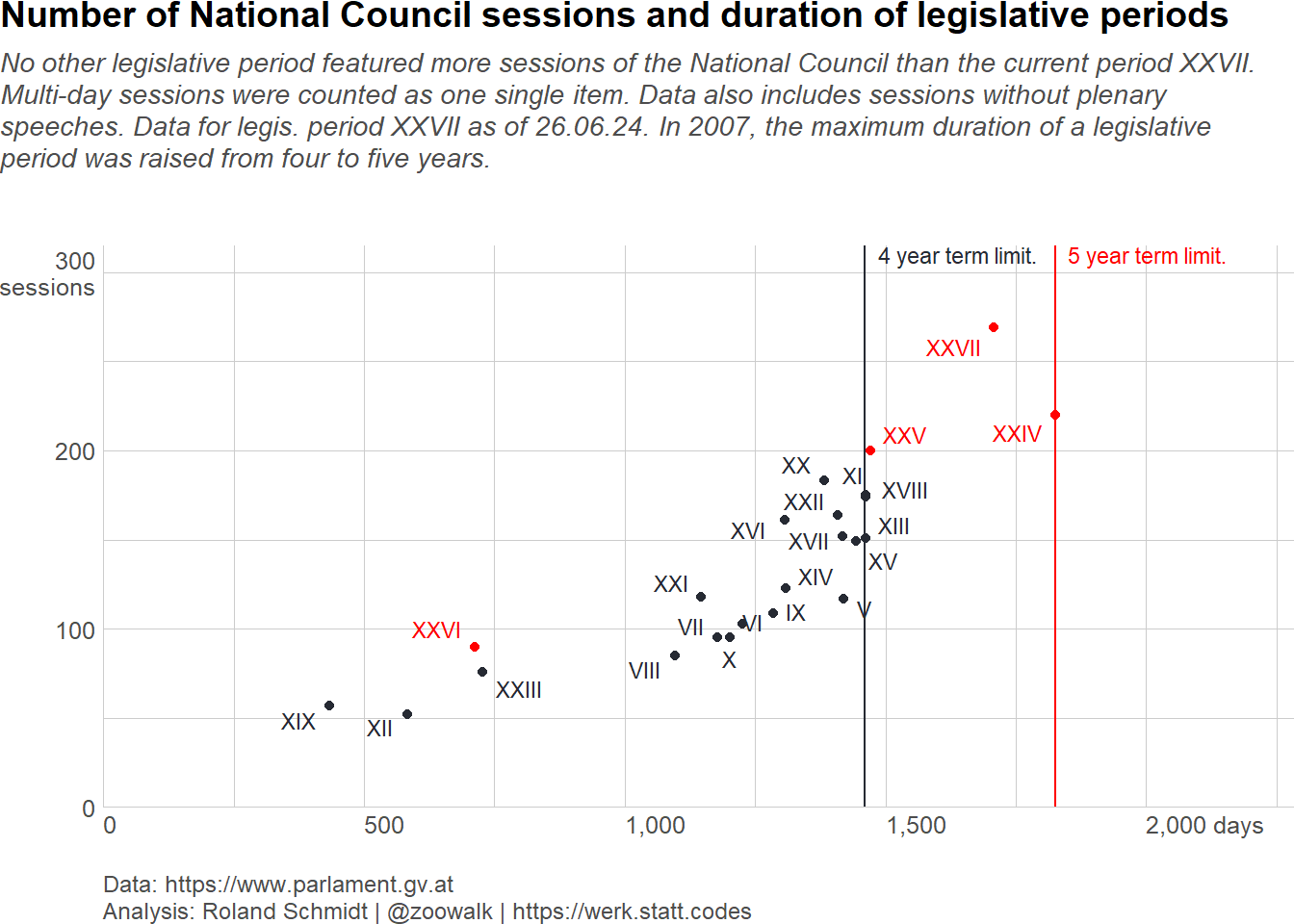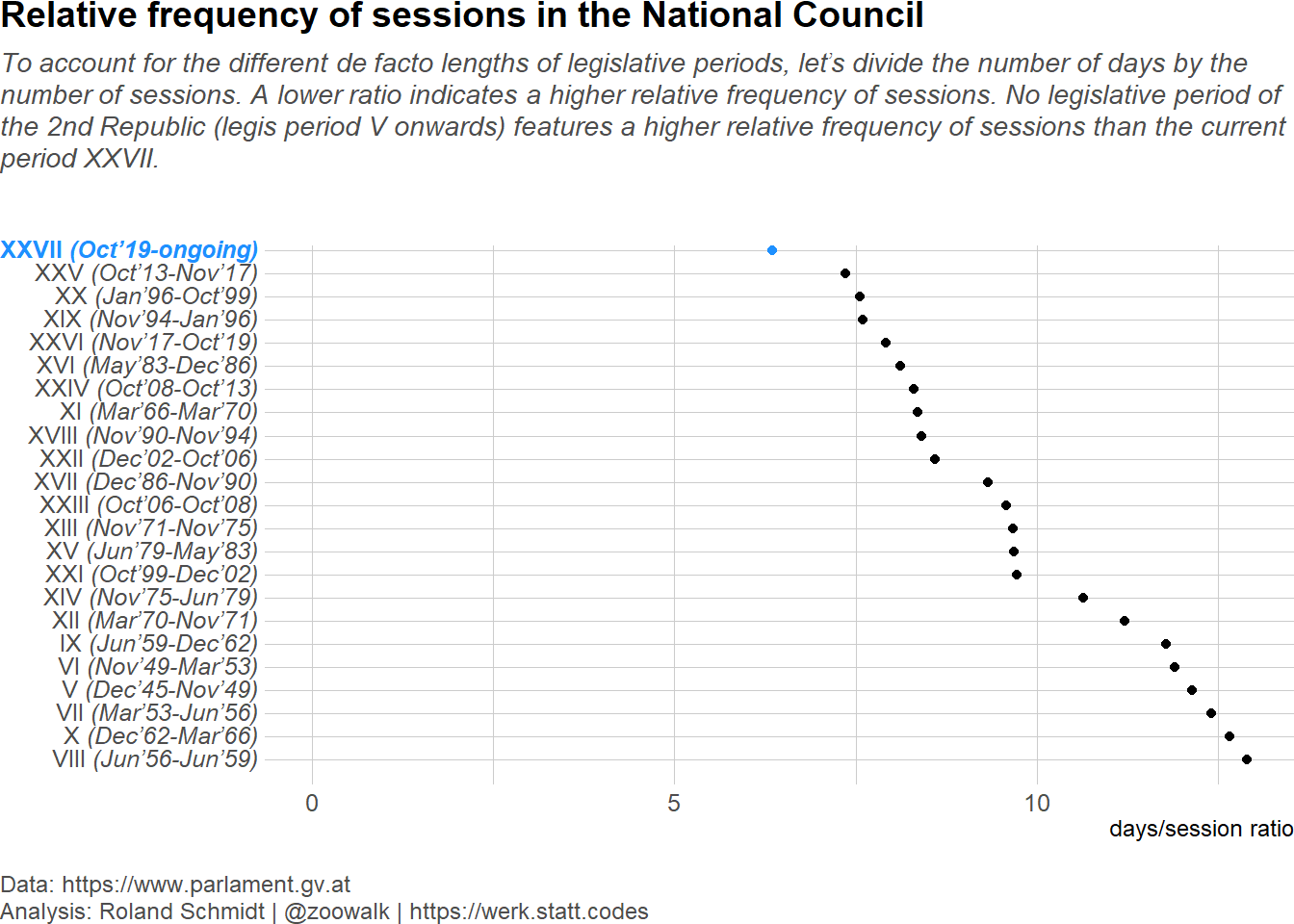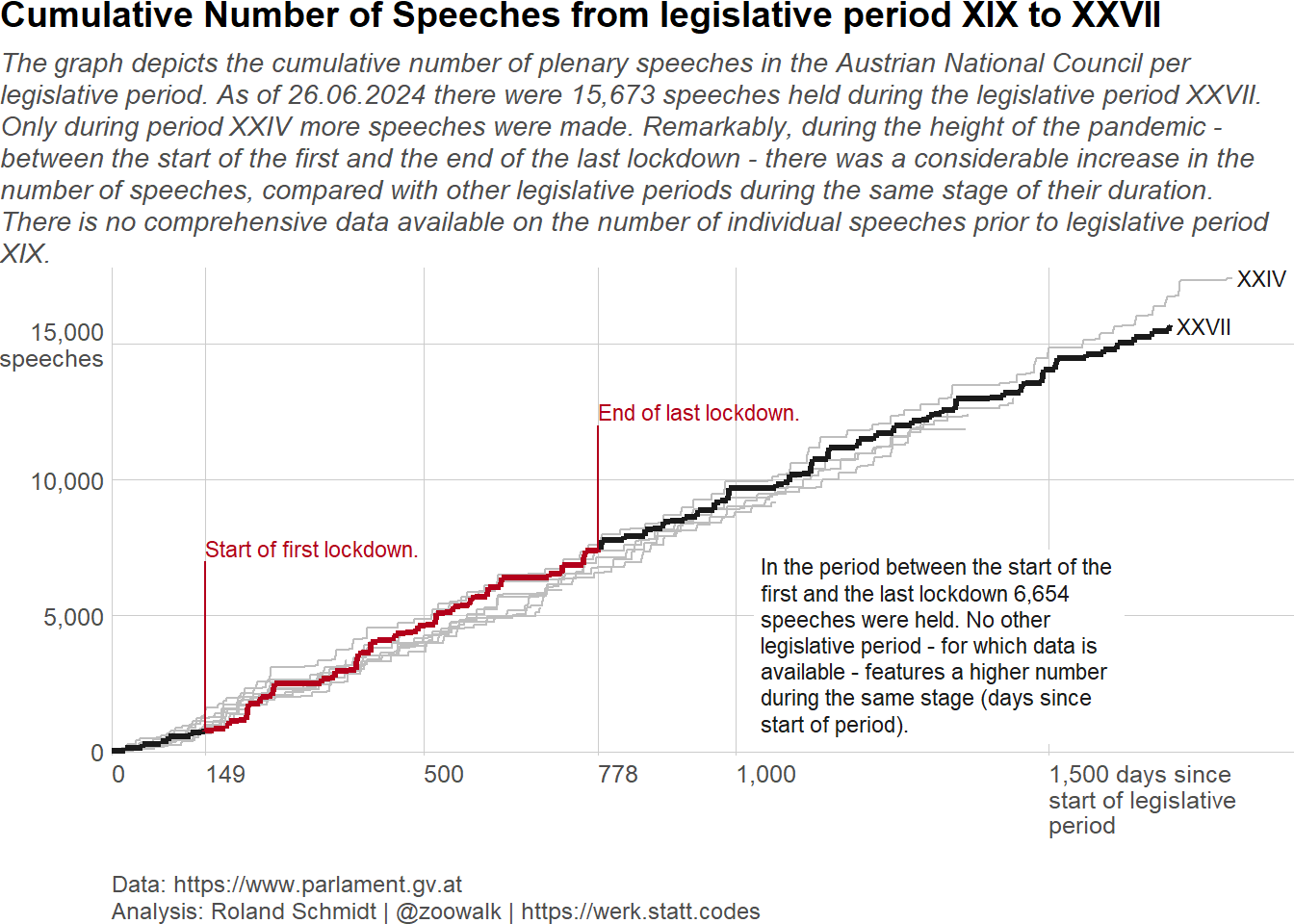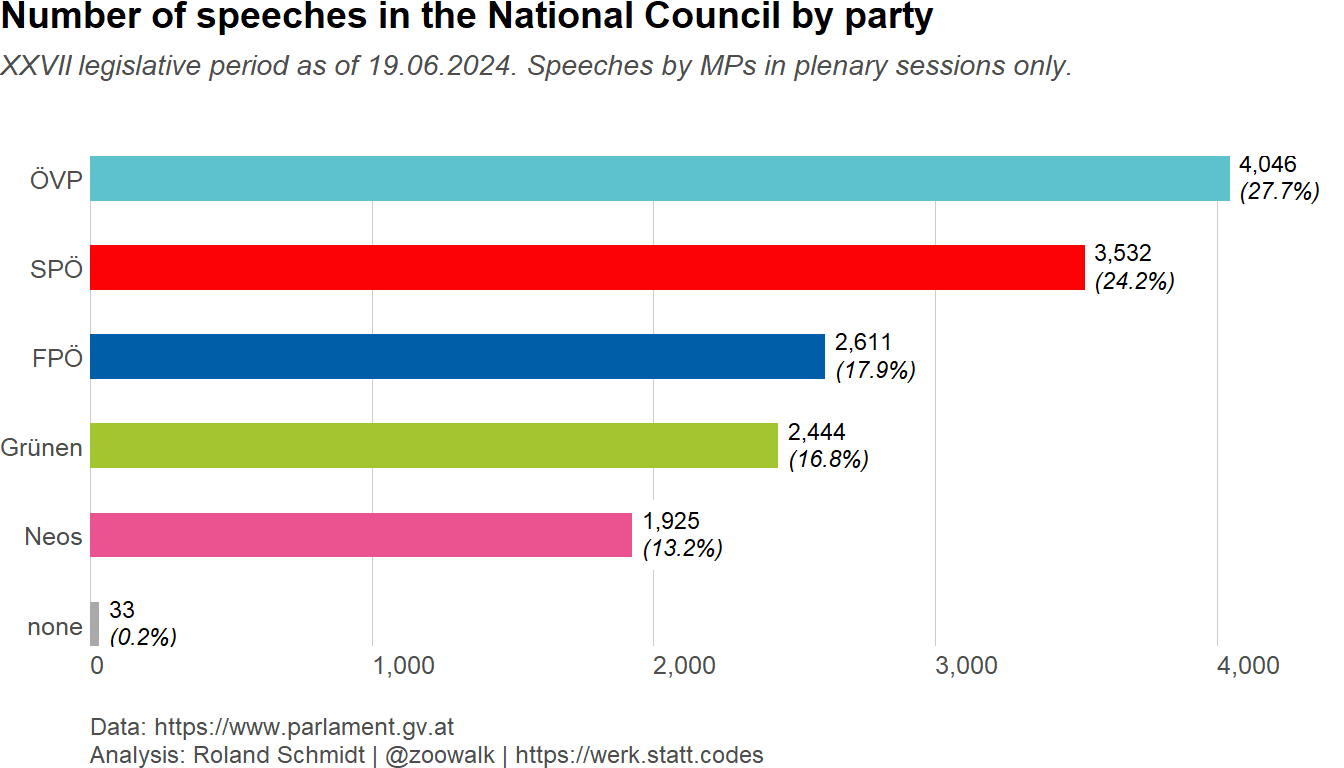
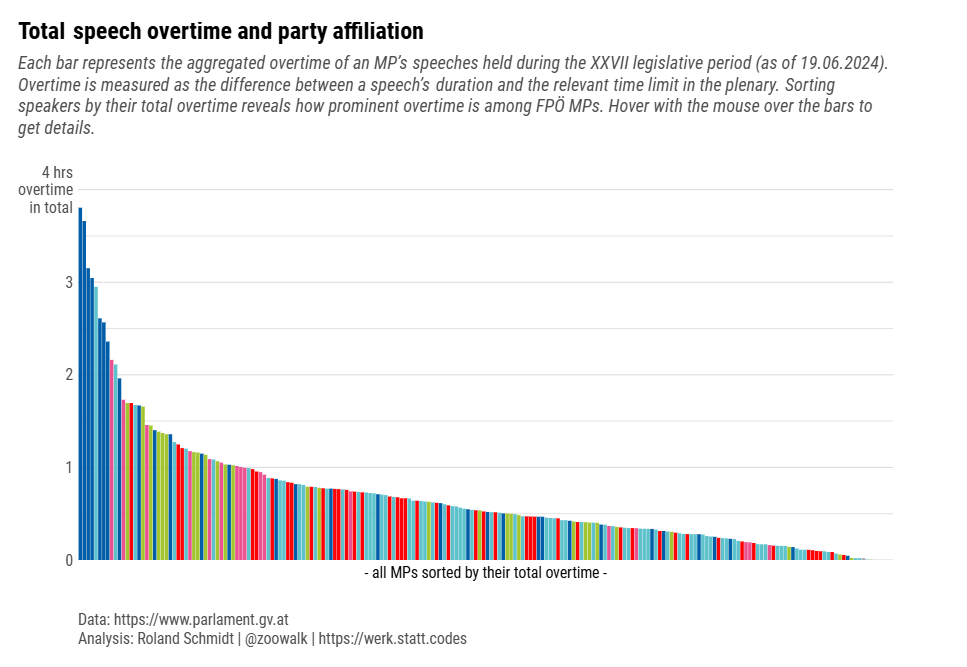
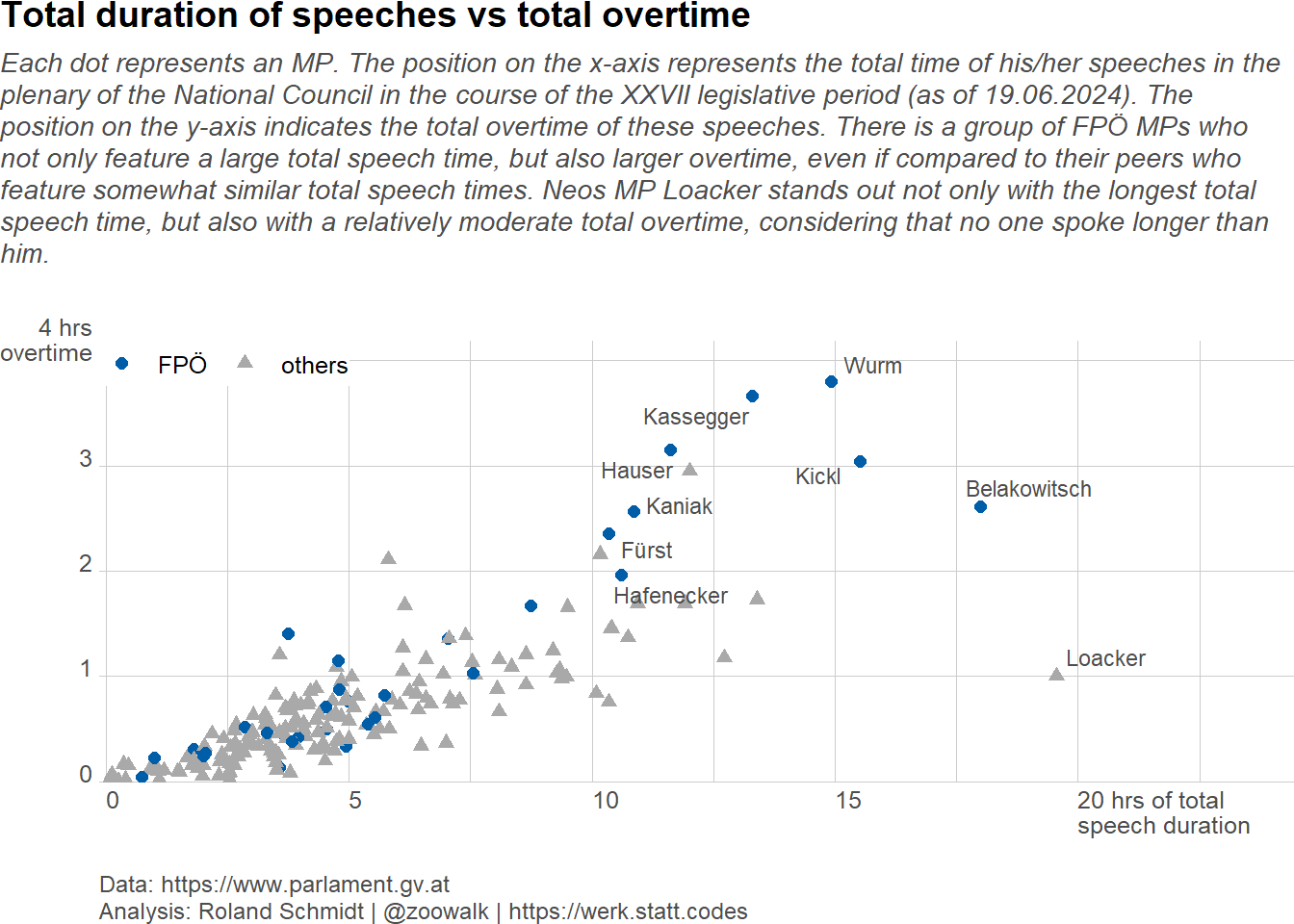
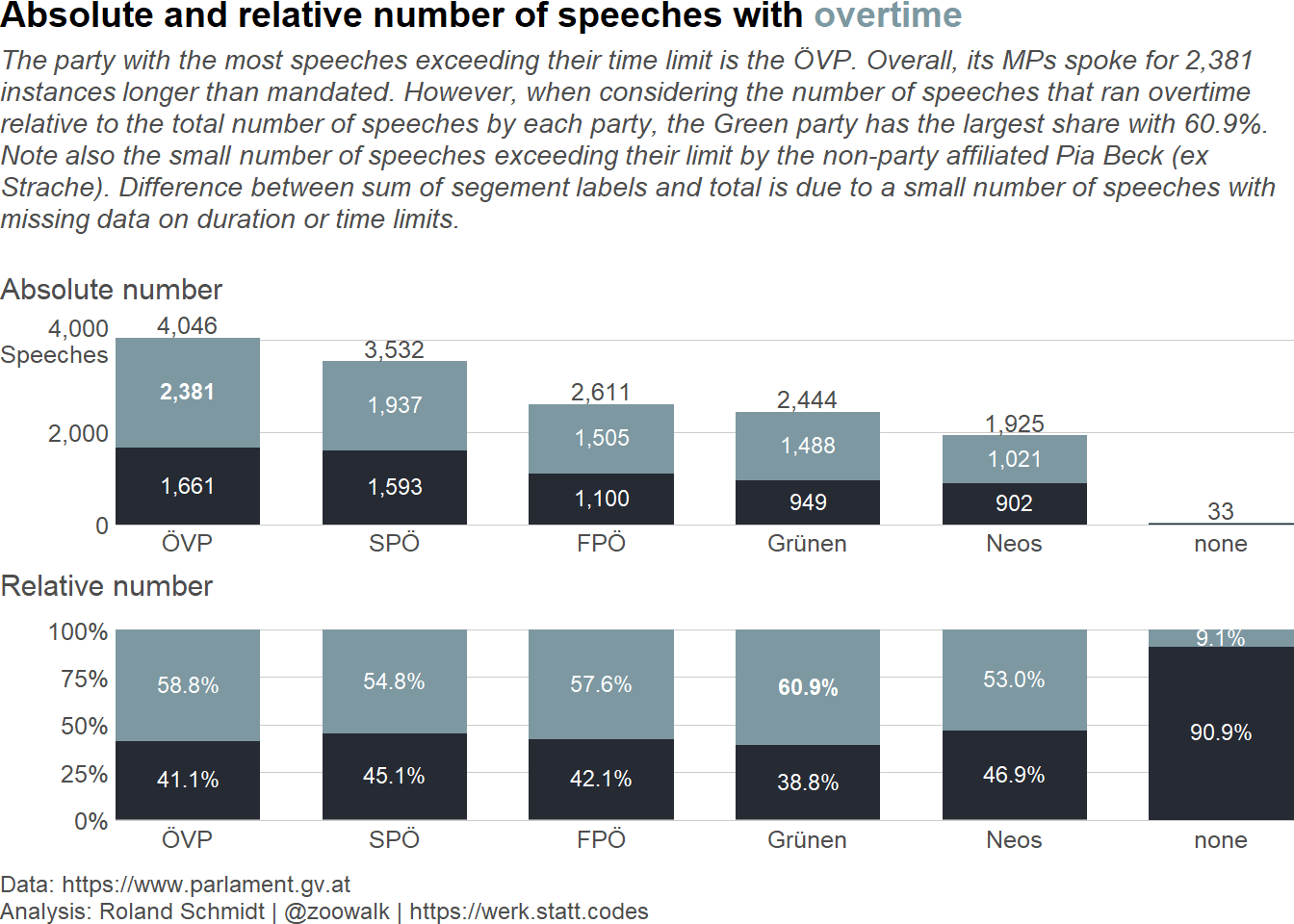
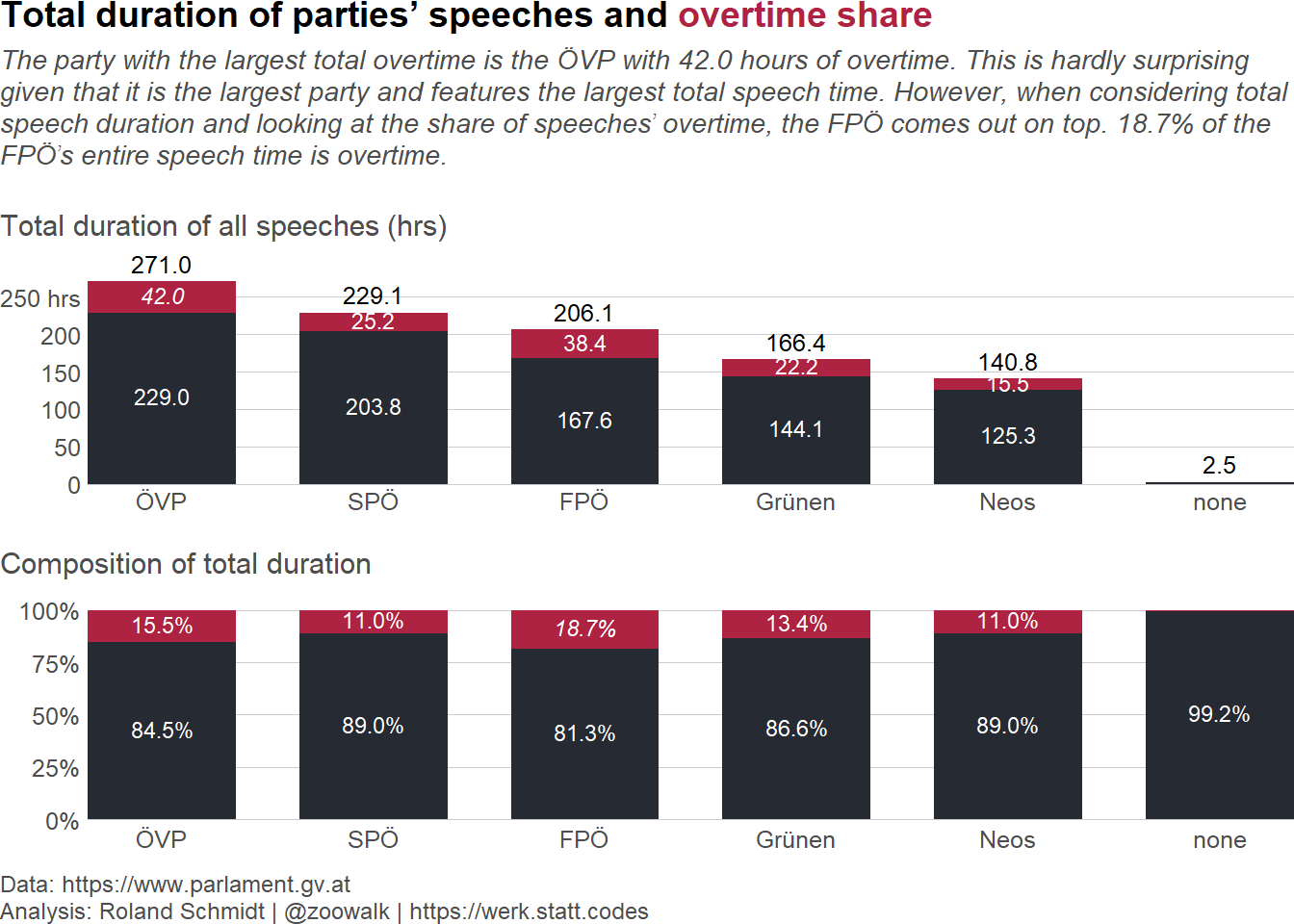

Load required packages, define auxiliary functions and plot theme
library(tidyverse, warn.conflicts = FALSE, quietly = TRUE)
library(httr2)
library(curl)
library(rvest)
library(reactable)
library(htmltools)
library(lubridate)
library(ggiraph)
library(clock)
library(reactablefmtr)
library(ggrepel)
library(ggtext)
library(tictoc)
library(furrr)
library(patchwork)
plan(multisession, workers = 3)
# define colors
col_bar <- "#262a33"
vec_party_colors <- c(
FPÖ = "#005DA8", Neos = "#EA5290", ÖVP = "#5DC2CC", SPÖ = "#FC0204", Grünen = "#A3C630",
none = "darkgrey"
)
# function inserting hyperlink in reactable
fn_reactable_url <- function(value, index) {
if (is.na(value)) {
# Option 1: Display nothing or some placeholder text
htmltools::tags$span("No link available")
# Option 2: Simply return an empty string or a non-clickable placeholder
# ""
} else {
htmltools::tags$a(
href = value,
"link",
target = "_blank"
)
}
}
# function inserting drop-down filter in reactable packages
fn_reactable_filter <- function(elementId) {
return(function(values, name) {
tags$select(
onchange = sprintf("Reactable.setFilter('%s', '%s', event.target.value || undefined)", elementId, name),
tags$option(value = "", "All"),
lapply(sort(unique(values)), tags$option),
"aria-label" = sprintf("Filter %s", name),
style = "width: 100%; height: 28px;"
)
})
}
# function to get MPs name
fn_get_name <- function(pad_intern) {
# pad_intern <- "35520"
url <- glue::glue("https://www.parlament.gv.at/person/{pad_intern}?json=TRUE")
txt <- jsonlite::fromJSON(url)
# listviewer::jsonedit(txt)
name_current <- txt$meta$description
name_previous <- txt$content$personInfo$frueherenamen %>% str_remove_all(., regex("[\\(\\)]"))
if (purrr::is_empty(name_previous)) {
return(name_current)
} else {
return(glue::glue("{name_current}({name_previous})"))
}
}
# define theme for plots
theme_post <- function() {
hrbrthemes::theme_ipsum_rc() +
theme(
plot.title = element_textbox_simple(size = rel(1.2), margin = ggplot2::margin(0, 0, .25, 0, unit = "cm")),
plot.subtitle = element_textbox_simple(size = rel(.9), color = "grey30", face = "italic", family='Roboto condensed',margin = ggplot2::margin(0, 0, b = 1, 0, unit = "cm")),
axis.title.x = element_blank(),
axis.title.y = element_blank(),
axis.text.y = element_text(size = rel(.8)),
axis.text.x = element_text(size = rel(.8)),
panel.background = element_rect(fill = "white", color = NA),
plot.background = element_rect(fill = "white ", color = NA),
panel.border = element_blank(),
plot.title.position = "plot",
plot.margin = ggplot2::margin(l = 0, 0, 0, 0, "cm"),
legend.position = "top",
legend.margin = ggplot2::margin(l = 0, 0, 0, 0, "cm"),
legend.justification = "left",
legend.location = "plot",
legend.title = element_blank(),
plot.caption = element_textbox_simple(hjust = 0, color = "grey30", margin=ggplot2::margin(t=0.5, unit="cm"))
)
}
theme_set(theme_post())
# theme_post() %>% listviewer::jsonedit()
txt_caption_graph <- "Data: https://www.parlament.gv.at<br>Analysis: Roland Schmidt | @zoowalk | <span style='font-weight:400'>https://werk.statt.codes</span>"
# function adding units to last axis label
fn_label_unit <- function(x, label) {
x <- as.character(x)
index_last_label <- max(which(!is.na(x)))
x[index_last_label] <- paste(x[index_last_label], label)
return(x)
}
df_lookup_wortmeldung <- c(
"wm" = "Wortmeldung in Plenarsitzung",
"un" = "Wortmeldung einer Unterzeichnerin bzw. eines Unterzeichners einer Aktuellen Stunde",
"rb" = "Wortmeldung eines Regierungsmitglieds",
"as" = "Wortmeldung in einer Aktuellen Stunde",
"c" = "Contra-Wortmeldung in einer Debatte",
"p" = "Pro-Wortmeldung in einer Debatte",
"el" = "Wortmeldung in einer Ersten Lesung",
"kd" = "Wortmeldung in einer kurzen Debatte",
"bg" = "Begründung eines Dringlichen Antrags in einer Plenarsitzung",
"da" = "Wortmeldung zu einer Dringlichen Anfrage",
"de" = "Wortmeldung zu einem Dringlichen Antrag",
"er" = "Regierungserklärung",
"tb" = "Tatsächliche Berichtigung in einer Plenarsitzung",
"rs" = "Wortmeldung einer ressortzuständigen Staatssekretärin bzw. eines ressortzuständigen Staatssekretärs im Rahmen der Budgetberatungen",
"et" = "Erwiderung auf eine tatsächliche Berichtigung in einer Plenarsitzung",
"gb" = "Wortmeldung zur Geschäftsbehandlung",
"rf" = "Wortmeldung eines ressortfremden Regierungsmitglieds bzw. einer Staatssekretärin oder eines Staatssekretärs im Rahmen der Budgetberatungen"
) %>%
enframe(name = "wortmeldungsart", value = "wortmeldungsart_long")