[1] "https://www.parlament.gv.at/PAKT/PLENAR/filter.psp?view=RSS&jsMode=&xdocumentUri=&filterJq=&view=&MODUS=PLENAR&NRBRBV=NR&GP=XXVII&R_SISTEI=SI&listeId=1070&FBEZ=FP_00"How to extract speeches held at Austria’s parliament
Austria
text analysis
web scraping
regex
The website of the Austrian parliament provides transcripts of its sessions. This post details how to extract the statements given by MPs, members of government and other speakers.
1 Context
This post is actually a spin-off of a another post, which got too long and convoluted (see here). The context is that I was recently interested in transcripts of sessions of Austria’s parliament and noticed that those of more recent legislative periods are not included in an already compiled dataset.1 Hence, the interest and need to dig into transcripts provided on the parliament’s website.
This post will lay out the necessary steps in R to get transcripts of multiple sessions from multiple legislative periods, and subsequently retrieve statements by individual speakers. The result, a file comprising all statements for the 16th and 17th legislative period (as of 3 Nov’21), is available for download here. If you use it, I would be grateful if you acknowledge this blog post. If you have any question or spot an error, feel free to contact me via twitter DM.
2 Get the links of all sessions of multiple legislative periods
The parliament’s website provides an overview of all sessions held during a specific legislative period here. Below a screenshot of the site for the current legislative period:
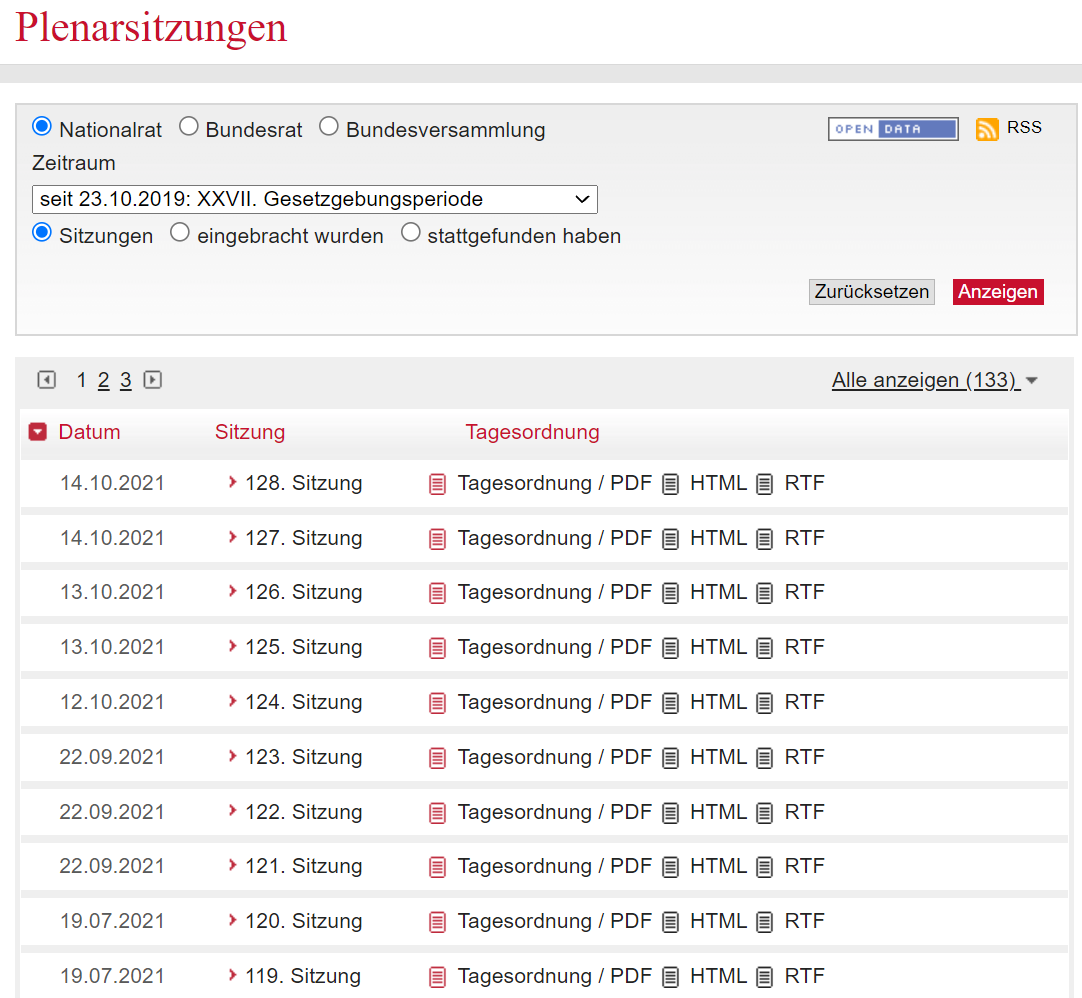
We can use this overview page to extract the links leading to each session’s details page which includes links to the transcripts. However, instead of scraping the links to the details page from the table, I used the data provided via the site’s RSS-feed. The provided XML-format is IMHO considerably more convenient to work with than fiddling with the table itself.
To get the link leading to the XML file, click on the RSS symbol. In the above example the address is
Since we might be also interested in sessions from other legislative periods, let’s have a look at the above link. As you can see, the query in the link contains the argument ‘GP=XXVII’, i.e. the XXVII legislative period. If we are interested in sessions of e.g. the XXVI legislative period as well, we will need to modify the link accordingly. This can be done relatively conveniently with the glue function:
https://www.parlament.gv.at/PAKT/PLENAR/filter.psp?view=RSS&jsMode=&xdocumentUri=&filterJq=&view=&MODUS=PLENAR&NRBRBV=NR&GP=XXVI&R_SISTEI=SI&listeId=1070&FBEZ=FP_007
https://www.parlament.gv.at/PAKT/PLENAR/filter.psp?view=RSS&jsMode=&xdocumentUri=&filterJq=&view=&MODUS=PLENAR&NRBRBV=NR&GP=XXVII&R_SISTEI=SI&listeId=1070&FBEZ=FP_007This vector, containing the links to both XML files which in turn contain the links leading to our session pages, has now to be fed into a function that actually extracts the links which we are interested in. The function below does this. Comments are inserted in the chunk.
Now let’s apply this function to the vector.
As a result we obtain a dataframe with 92 rows (links to sessions’ details pages) in total.
If you have a look at the screenshot from above, you’ll see that we got indeed all session of the current legislative period as of the time of writing.
3 Extract links leading to transcripts
As you could already see in the function fn_get_session_links above, the link_records not only comprises the link to the session’s details page, but was complemented by the expression #tab-Sten.Protokoll at the end. The reason for this addition is that the actual link leading to the session’s transcript is located at a distinct tab on the session’s details page. Below a screen shot for an example:
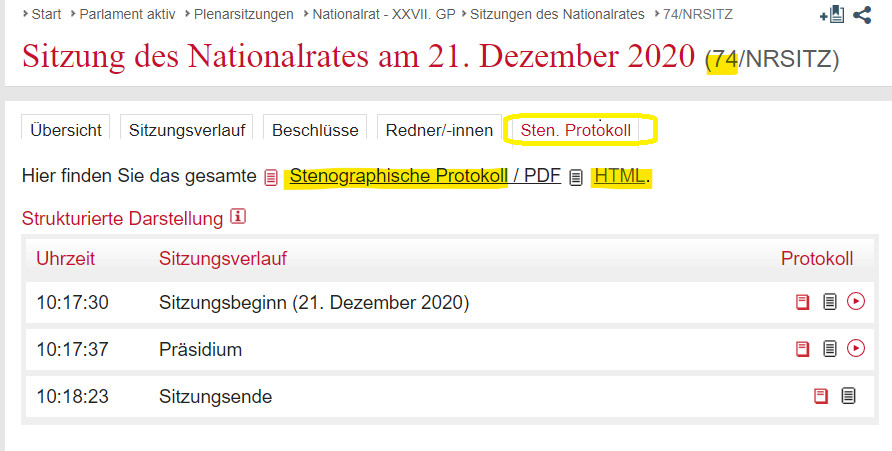
In the next step we have to retrieve the link finally leading us to the transcript. If we hover over the link leading to the HTML version of the ‘Stenographisches Protokoll’ (stenographic transcript), we can see that the address e.g. for the transcript of the 74th session is
[1] "https://www.parlament.gv.at/PAKT/VHG/XXVII/NRSITZ/NRSITZ_00074/fnameorig_946652.htm"However, since we are not only interested in this particular case, but also in the links pertaining to other sessions we need to find a way to retrieve all the links in question by means of a general query. The code below does this.
We first extract all (!) links contained on the transcript tab with the rvest package, and then filter out the relevant link with the regular expression "\\/NRSITZ_\\d+\\/fnameorig_\\d+\\.html$".
In the next step let’s apply this function to all links leading to submissions’ details page/the tab for transcripts. Note that I used the furrr package enabling us to apply the function in parallel rather than sequentially and hence accelerate things a bit.
What we obtain is a dataframe with the links to all transcripts.
Note that there are some sessions where no link to a transcript could be retrieved. A look at these sessions’ dates reveals that the missing links pertain to the most recent sessions. The finalized transcripts are only available after some delay. We remove these missing observations.
3.1 Account for multi-day sessions
There is one further thing which we have to control for: Some sessions last for several days. While we have a single observation (row) for each day, the transcript for each day covers the entire session and not only the statement from the day in question. If we do not account for this, statements of e.g. a three days spanning session would be included three times into the dataset. Below those sessions which lasted multiple days.
To control for this, I collapse duplicate links.
Code
df_link_text<- df_link_text %>%
group_by(legis_period, link_to_text, link_records) %>%
arrange(date_session, .by_group = T) %>%
summarise(date_session=paste(date_session, collapse=", "),
session_name=paste(unique(session_name), collapse=", "),
date_n=n()) %>%
ungroup() %>%
#takes first date if session span over multiple days; later needed for sorting etc
mutate(date_first=str_extract(date_session, regex("^[^,]*"))) %>%
mutate(date_first=lubridate::ymd(date_first))4 Extract text from transcripts
Now, with the links to the actual texts available, we have to feed them into a function which actually retrieves the latter. The function below does this. Again, the rvest package is our tool of choice to extract the content of the html file.
The somewhat tricky part here is to identify the relevant css-selector enabling us to retrieve the parts we are interested in. Navigate to one sample page, open the inspect tools (F12), and select the item of interest.

In the screen recording above we see that the statement by MP Drozda can be selected with the css-selector WordSection27. Other statements have e.g. WordSection28, WordSection60 etc. In other words, every statement has its own distinct selector/css class. At first glance, this looks like troubles ahead. ‘Luckily’ though, the html_nodes syntax allows us to specify something like a regex pattern: [class^=WordSection], i.e. take only those classes which start with WordSection. With this approach, we are able to select all our statements even if each of their css-selector is unique (ends with a distinct number). Sweet, no?2
Let’s define the function accordingly:
And then apply it:
The first five rows of the resulting dataframe are below:
5 Extract statements
Note that the entire transcript of one session is contained in the new column/cell text as a nested dataframe (list column; in the table above they are displayed as [object Object]).
[1] "list"Hence, we need to unnest this list column.
What we get is a new dataframe with one row per ‘item’ in the transcript. Each item is an instance of the css class WordSection as defined in our rvest request. A quick look at the result, however, reveals that these items not only include statements in which we are interested, but also headings, the table of contents, and other parts of the transcript which are irrelevant for our focus. The chunk below shows the first ten rows of one session. There’s plenty of text which actually is not from a statement of a speaker.
Code
df_data_long %>%
slice_head(., n=10) %>%
select(legis_period, date_session, session_name, text_raw) %>%
reactable(.,
theme=nytimes(cell_padding=0),
columns = list(
legis_period=colDef(width=100),
date_session=colDef(format=colFormat(date=T, locales="de-De"),
width = 100),
session_name=colDef(width=100),
text_raw=colDef(width=400)),
height=500) The challenge now is to filter the dataframe in such a way that we eventually obtain only the rows we are interested in, i.e. to distinguish between rows containing statements and rows containing other text.
5.1 Filter out rows of interest
Below the code doing the heavy lifting, including inline comments.
Code
#define regex for page headers which have to be removed
regex_page_header <- regex("Nationalrat, [XVI]{2,5}\\.GPS.*?Seite \\d+")
#define regex picking up the text of a motion which is inserted in the transcript; I also remove them; speakers don't read out the entire motion;
regex_petition_text <- regex("Der Antrag hat folgenden Gesamtwortlaut:.*$")
#select only those rows which are statements/speeches
df_text_filtered <- df_data_long %>%
#remove those rows which start with "Abstimmung" (=vote)
filter(!str_detect(str_extract(text_raw, regex("[:alpha:]+")), regex("^Abstimm"))) %>%
#remove from the raw text the page header and page footer
mutate(text_raw=str_remove_all(text_raw, regex_page_header)) %>%
#remove text of motions; they are included in the transcript, but are not actually read out by the speakers
mutate(text_raw=str_remove_all(text_raw, regex_petition_text)) %>%
mutate(text_raw=str_trim(text_raw, side=c("both"))) %>%
#remove rows which include "Stenographisches Protokol"; refer to headers etc
filter(!str_detect(text_raw, regex("Stenographisches Protokoll"))) %>%
#remove soft hyphen; invisible signs introducing line breaks which we do not need and otherwise distort search results
mutate(text_raw=str_remove_all(text_raw, regex("\\p{Cf}+"))) %>%
mutate(row_id=row_number())
#extract period and session
df_text_filtered <- df_text_filtered %>%
#include legislative period again
mutate(legis_period=str_extract(link_to_text, regex("(?<=VHG\\/)[^\\/]*")),
.before=date_session) %>%
#create a session_id for easier data management
mutate(session_id=str_extract(link_to_text, regex("(?<=NRSITZ_)\\d+")) %>%
as.numeric(),
.after=legis_period) %>%
relocate(session_name, .after=session_id) %>%
arrange(legis_period, session_id) %>%
ungroup() %>%
mutate(row_id=row_number()) After this process we reduced our dataframe from 29,263 to 28,855 rows.
Code
nrow(df_data_long)[1] 29263Code
nrow(df_text_filtered)[1] 288555.2 Extract speakers
In the next step, I’ll retrieve the name of the speakers from the extracted strings. As the sample output below shows, the speaker’s name is always contained in the opening text section before a colon, after which the actual statement starts. I’ll later call this part of the row speaker_prep.
# A tibble: 5 × 1
text_raw
<chr>
1 19.50.16 Abgeordneter Andreas Minnich (ÖVP): Frau Präsidentin! Sehr geehrte F…
2 16.48.21 Abgeordnete Mag. Selma Yildirim (SPÖ): Sehr geehrter Herr Präsident!…
3 9.06.51 Abgeordneter Karl Schmidhofer (ÖVP): Ich gelobe.
4 18.18.56 Abgeordneter Hannes Amesbauer, BA (FPÖ): Sehr geehrte Frau Präsident…
5 Präsidentin Doris Bures: Als Nächster gelangt Herr Abgeordneter Douglas Hoyos…5.2.1 Compile dataset containing all members of government and parliament
To be able to extract the names of the speakers, I needed to create a dataframe containing the name of all MPs and government members for each legislative period. Subsequently, I’ll check whether any of these names is present in the opening section of a statement by using the regex_left_join function from the fuzzyjoin package.
The data on MPs I retrieve from Flooh Perlot’s (@drawingdata) pertaining github repository; the data on members of government is extracted from a repository I created after scraping the data from the parliament’s website. If you unfold the code chunk below, you’ll see the required steps.
5.2.2 Fuzzy-join
Now, let’s use fuzzyjoin::regex_left_join and see whether a name of an MP or government member shows up in the opening section of the extracted text string.
Code
df_text_filtered_speaker <- df_text_filtered %>%
# create a helper column to make work a bit easier; take everything before the first colon
mutate(speaker_prep=str_extract(text_raw, regex("^[^\\:]*\\:")) %>%
#remove time stamp at beginning
str_remove(., regex("\\d+\\.?\\d+\\.?\\d+")) %>%
#removing characters which are erroneously enocded/retrieved from web
str_remove_all(., regex("†")) %>%
#removes an error when parsing the website (e.g. Sobotka, row_id 2896, 3041)
str_remove_all(., regex("\\|")) %>%
str_remove_all(., regex("\\*+")) %>%
#corrects row_id 4694; Sobotka - das Glockenzeichen -
str_remove_all(., regex("\\p{Pd}.*?\\p{Pd}")) %>%
#row_id 23158; arbitrary word in speaker_prep
str_remove(., regex("Einlauf")) %>%
str_trim(., side=c("both"))) %>%
#create a unique id for each row; I'll need that later when it comes to combining separated statements
mutate(row_id=row_number()) %>%
select(row_id, legis_period, date_session, date_first, session_id, session_name, speaker_prep,
text_raw, link_records, link_to_text)
library(fuzzyjoin)
#find whether names of office holders are in speaker_prep;
df_extract <- df_text_filtered_speaker %>%
regex_left_join(.,
df_office %>%
select(name_clean,
body,
office_position=position,
ministry,
office_period,
speaker_party=party),
by=c(speaker_prep="name_clean")) %>%
rename(speaker=name_clean)The result is quite good, but not perfect. There were only 82 instances in which no speaker could be identified.
FALSE TRUE
93147 82 These instances can be traced back to 19 distinct cases, which overwhelmingly concern speakers who were not members of the Austrian Parliament or Government. I will revisit these cases at a later stage.
# A tibble: 19 × 2
speaker speaker_prep
<chr> <chr>
1 <NA> Mitglied des Europäischen Parlaments Mag. Evelyn Regner (SPÖ):
2 <NA> Präsidentin des Rechnungshofes Dr. Margit Kraker:
3 <NA> <NA>
4 <NA> Wir gelangen somit gleich zur Abstimmung über den Gesetzentwurf samt…
5 <NA> Mitglied des Europäischen Parlaments Karin Ingeborg Kadenbach (SPÖ):
6 <NA> Mitglied des Europäischen Parlaments Mag. Dr. Georg Mayer, MBL-HSG (…
7 <NA> Präsidentin der Parlamentarischen Versammlung des Europarates Lilian…
8 <NA> Präsidentin der Parlamentarischen Versammlung des Europarates Lilian…
9 <NA> Somit kommen wir zur Abstimmung, die ich über jeden Verhandlungsgege…
10 <NA> Bundesministerin für Bildung, Wissenschaft und Forschung Mag. Dr. Ir…
11 <NA> Bevor ich diese Sitzung schließe, gebe ich noch bekannt, dass im Ans…
12 <NA> Mitglied des Europäischen Parlaments Dr. Monika Vana (Grüne):
13 <NA> Mitglied des Europäischen Parlaments Dr. Monika Vana (fortsetzend):
14 <NA> Mitglied des Europäischen Parlaments Barbara Thaler (ÖVP):
15 <NA> Volksanwalt Mag. Bernhard Achitz:
16 <NA> Mitglied des Europäischen Parlaments Mag. Dr. Georg Mayer, MBL-HSG (…
17 <NA> Mitglied des Europäischen Parlaments Mag. Dr. Günther Sidl (SPÖ):
18 <NA> Mitglied des Europäischen Parlaments Mag. Lukas Mandl (ÖVP):
19 <NA> Präsidentin des Rechnungshofes Rechnungshof Dr. Margit Kraker: 5.2.3 Multi-period members
The regex_left_join above yielded a match whenever the name of a member of parliament or government appeared in the first section of an extracted item. However, with this approach we end up with duplicates for some observations. Some MPs have changed party affiliation, or their party’s name changed during their time in parliament. Similarly, some MPs had interrupted memberships in parliament (resulting to multiple membership entries). Consequently, the dataset on office holders contains multiple rows for one and the same MP. This results in multiple matches. In fact we obtained 93,229, instead of 28,855 rows!
To control for this source of error, we keep only those matches where the date of the statement falls into the speaker’s period of office. (A consequence of this approach is that we lose those rows where we were previously unable to identify a speaker; again, more on that later).
Code
df_extract_2 <- df_extract %>%
filter(date_first %within% office_period)# A tibble: 4 × 5
# Groups: speaker [2]
row_id date_session speaker speak…¹ office_period
<int> <chr> <chr> <chr> <Interval>
1 5870 2018-10-18 Beate Meinl-Reisin… NEOS 2018-09-27 UTC--2023-01-01 UTC
2 5872 2018-10-18 Beate Meinl-Reisin… NEOS 2018-09-27 UTC--2023-01-01 UTC
3 35 2017-11-09 Nikolaus Scherak NEOS 2014-01-30 UTC--2023-01-01 UTC
4 93 2017-12-13 Nikolaus Scherak NEOS 2014-01-30 UTC--2023-01-01 UTC
# … with abbreviated variable name ¹speaker_party5.2.4 Multi-office members
After this step we still end up with more matches/rows (28,882) than we initially had statements (28,855). Why is this? Well, some speakers have more than one position. e.g. the current Austrian Vice-Chancellor Kogler is not only Vice-Chancellor, he is also Minister for Arts, Culture, Public Administration and Sport (don’t ask me how they put these ministries together). In other words, there are two rows for Werner Kogler as member of the government during the same period of time which will result in two matches for one single statement. To solve this, I’ll collapse these duplicates into one observation with a composite position, i.e. ‘Vice-Chancellor, Minister for….’.
Code
df_extract_2 <- df_extract_2 %>%
group_by(row_id) %>%
add_count() %>%
relocate(n, .after="row_id") %>%
relocate(office_period, .after="date_session") %>%
relocate(office_position, .after="office_period") %>%
relocate(speaker, .after="office_period") %>%
ungroup()
df_extract_3 <- df_extract_2 %>%
group_by(across(.cols=c(everything(),
-office_period,
-office_position,
-ministry,
-speaker_party,
-body
))) %>%
summarise(office_position=paste(office_position, collapse="/"),
ministry=paste(ministry, collapse="/"),
speaker_party=paste(speaker_party, collapse=",")) %>%
ungroup()So how do we fare now, did we get rid of all noise created by the fuzzjoin?
# A tibble: 1 × 3
initial merged_position diff
<int> <int> <int>
1 28855 28726 -129The results is somewhat puzzling since we have now 129 rows less than before. How can this be?
5.3 Adding non-MPs/non-Gov speakers
Code
df_non_mp_gov_speakers <- df_text_filtered_speaker %>%
anti_join(., df_extract_3,
by=c("row_id"))If we contrast our results with our initially extracted dataframe of statements, I find 129 rows which are now missing. These missing rows are statements where we previously were unable to identify a speaker. A glimpse at the text before the first colon (speaker_prep) reveals that almost all of these rows concern speakers who are neither MPs nor members of the Government, but e.g. members of the European Parliament, the Office of the Ombudsman, the Court of Audit etc. who can also give statements in the chamber.
# A tibble: 37 × 1
speaker_prep
<chr>
1 Mitglied des Europäischen Parlaments Dr. Othmar Karas, MBL-HSG (ÖVP):
2 Mitglied des Europäischen Parlaments Mag. Evelyn Regner (SPÖ):
3 Mitglied des Europäischen Parlaments Mag. Dr. Angelika Mlinar, LL.M (NEOS):
4 Präsidentin des Rechnungshofes Dr. Margit Kraker:
5 <NA>
6 Volksanwältin Dr. Gertrude Brinek:
7 Volksanwalt Dr. Peter Fichtenbauer:
8 Volksanwalt Dr. Günther Kräuter:
9 Mitglied des Europäischen Parlaments Mag. Dr. Angelika Mlinar, LL.M. (NEOS):
10 Wir gelangen somit gleich zur Abstimmung über den Gesetzentwurf samt Titel u…
# … with 27 more rowsTo get the names of these speakers, I’ll extract the required information via regular expressions from these missing rows, and subsequently add them to our previously obtained data set (where we were able to identify speakers).
Code
df_non_mp_gov_speakers <- df_non_mp_gov_speakers %>%
mutate(speaker=str_remove(speaker_prep, regex("\\:")) %>%
#remove brackets
str_remove(., regex("\\([^\\)]*\\)")) %>%
str_trim(., side=c("both")) %>%
#remove everything after last comma
str_remove(., regex(",[^,]*$")) %>%
#extract last two words (assuming name only two words)
str_extract(., regex("\\w+\\s+\\w+$"))) %>%
#these speakers originate neither from parliament nor government; hence "other"
mutate(body="other") %>%
#but they can be affiliated to a party, e.g. MEPs
mutate(speaker_party=str_extract(speaker_prep, regex("(?<=\\()[^\\)]*(?=\\)\\:)"))) %>%
mutate(speaker_party=case_when(is.na(speaker_party) ~ "none",
TRUE ~ as.character(speaker_party))) %>%
#extract the position:
mutate(office_position=speaker_prep %>%
#remove name from speaker_prep; results with position plus noise
str_remove(., speaker) %>%
str_remove(., regex(":")) %>%
#remove academic titles
str_remove_all(., regex("\\S+\\.")) %>%
#remove bracket terms
str_remove(., regex("\\(.*?\\)")) %>%
#remove everything after comma (problem with ministers who are wrongly parsed)
str_remove(., ",.*$") %>%
str_trim())
df_data <- bind_rows(df_extract_3,
df_non_mp_gov_speakers)Combining those two datasets results in a dataframe with the exact same number of statements as initially obtained from the web scraping: 28855. The noise introduced by the fuzzyjoin has hence been removed.
[1] 06 Revising speaker details
We have now a dataframe where each row is a distinct statement; the name of the speaker is extracted, and his/her position, party affiliation and institutional body are identified. However, a few revisions are needed.
First, one detail which needs to be revisited is that of the speaker’s position. Initially, we obtained speakers’ positions by matching the opening sections in the raw statement text (speaker_prep) with names from the dataframe on members of parliament and government (with the latter also including information on speakers’ positions). While this approach worked generally fine, there are MPs who were later elected for other positions, and hence their qualification as MP becomes misleading. This concerns e.g. the president and vice-presidents of the chamber (who are elected from the pool of MPs), or rapporteurs (‘Berichterstatter’) and committee/working group secretaries (‘Schriftführer’) who are MPs, but act for a specific task in a non-partisan function. Hence these changes to speakers’ position have to be corrected.
Second, as indicated above, there are a few speakers who held multiple functions at the same time. In general, this is not a big issue, e.g. as explained the Vice-Chancellor can also be minister and when making a statement, there is no explicit differentiation between his two positions. However, there are a very few cases, where an individual was an MP and a member of government on the same day, e.g. Sebastian Kurz as an MP made a brief statement before becoming - later in the day - chancellor. In such a case, it would be wrong to assign such a statement both positions (since a member of gov is not a member of parliament). Hence, the speaker’s details have to be corrected.
Whether a speaker actually acts as (vice)president, rapporteur or MP or chancellor is indicated in the starting segment before the actual statement (speaker_prep, text before the first colon). If this description is not the same as in the office_position column, the values have to be corrected. The code chunk below does this (and a few other things).
Code
df_position_rev <- df_data %>%
#corrects cases of Kurz (Chancellor and Abgeordneter on same day)
mutate(office_position=case_when(
str_detect(speaker_prep, regex("^Abgeor")) ~ "Abgeordnete/r",
TRUE ~ as.character(office_position)
)) %>%
#get those MPs where position and position in speaker's identification don't match
filter(str_detect(office_position, "Abge")) %>%
filter(!str_detect(speaker_prep, regex("Abge"))) %>%
distinct(speaker_prep, speaker, office_position) %>%
#correct the position by extracting the position as stated in speaker_prep
#by removing name, title etc from speaker_prep; what remains is actual position;
mutate(office_position_corr=speaker_prep %>%
#remove name of speaker
str_remove(., speaker) %>%
str_remove(., regex(":")) %>%
#remove bracket terms
str_remove_all(., regex("\\(.*?\\)")) %>%
#remove titles
str_remove_all(., regex("\\S*\\.")) %>%
#remove part were an editorial error in one row
str_remove(., regex("\\-.*?\\-")) %>%
str_trim) %>%
mutate(office_position_corr=case_when(
office_position=="Abgeordnete/r" ~ str_remove(office_position_corr, regex(",.*$") %>%
str_trim()),
TRUE ~ as.character(office_position_corr)
))
#merge result from above to original dataset; insert corrected position;
df_data <- df_data %>%
rename(office_position_orig=office_position) %>%
left_join(.,
df_position_rev %>%
select(speaker_prep, office_position_corr),
by="speaker_prep") %>%
#correct office_position
mutate(office_position=case_when(
is.na(office_position_corr) ~ office_position_orig,
TRUE ~ office_position_corr)) %>%
#corrects for Kurz who was MP and chancellor on the same day
mutate(office_position=case_when(
str_detect(speaker_prep, regex("^Abgeor")) ~ "Abgeordnete/r",
str_detect(office_position, regex("^Bericht")) ~ "Berichterstatter",
TRUE ~ as.character(office_position))) %>%
#correct body
mutate(body=case_when(
str_detect(office_position, regex("minister|kanzler|staatssekr",
ignore_case = T)) ~ "government",
str_detect(office_position, regex("^Abgeord|Schriftführ|^Präsident(in)?$|^Bericht")) ~ "parlament",
TRUE ~ as.character("other"))) %>%
#correct ministry
mutate(ministry=case_when(
#corrects for Kurz who was MP and chancellor on the same day
str_detect(office_position, "^Abge") ~ NA_character_,
ministry=="NA" ~ NA_character_,
TRUE ~ as.character(ministry)
)) %>%
select(-office_position_corr, -office_position_orig) %>%
#we have not data on gov members party affiliation;
#if MP than there is no NA in party affiliation which would originate from gov membership
mutate(speaker_party=case_when(str_detect(office_position, "Abge") ~
str_remove_all(speaker_party, "NA") %>%
str_remove(., ",") %>%
str_trim(),
body=="government" ~ NA_character_,
TRUE ~ as.character(speaker_party)))Here some of the results:
# A tibble: 25 × 3
speaker_prep speaker offic…¹
<chr> <chr> <chr>
1 Präsidentin Doris Bures: Doris B… Präsid…
2 Schriftführer Wolfgang Zanger: Wolfgan… Schrif…
3 Präsidentin Elisabeth Köstinger: Elisabe… Präsid…
4 Schriftführerin Angela Lueger: Angela … Schrif…
5 Schriftführerin Mag. Michaela Steinacker: Michael… Schrif…
6 Präsident Mag. Wolfgang Sobotka (den Vorsitz übernehmend): Wolfgan… Präsid…
7 Präsident Mag. Wolfgang Sobotka: Wolfgan… Präsid…
8 Präsidentin Anneliese Kitzmüller: Annelie… Präsid…
9 Schriftführer Hermann Gahr: Hermann… Schrif…
10 Präsident Mag. Wolfgang Sobotka (das Glockenzeichen gebend): Wolfgan… Präsid…
# … with 15 more rows, and abbreviated variable name ¹office_position7 Pending issues and improvements
By now we’re almost done. However, doing a few tests to check our results reveal that there are some statements which weren’t properly extracted.
# A tibble: 38 × 2
office_position n
<chr> <int>
1 Besonders verstört bin ich übrigens auch 1
2 Bevor ich diese Sitzung schließe 1
3 Bundeskanzlerin 1
4 Bundesminister für Europa, Integration und Äußeres 1
5 Mitglied des Europäischen Parlaments Karin 1
6 Präsidentin des Rechnungshofes Rechnungshof 1
7 Somit kommen wir 1
8 Staatssekretärin im Bundeskanzleramt 1
9 Vizekanzler 1
10 Vizekanzler/Bundesminister/Betraut mit der Vertretung der Bundesminist… 1
# … with 28 more rows[1] 4Overall, there are 4 out of 28,855 rows where the result is obviously wrong. As far as I can tell, these errors occur when two distinct statements are lumped together into one row, i.e. into the same html_nodes/class ‘WordSection’ (see above). Why this is the case, I can’t tell for sure, but it seems a bit like a formatting mishap on the side of the transcripts’ authors.
Since these errors are rather small (0.00347% in terms of rows, or 0.0012% in terms of all words spoken) and this post anyway is already much longer than originally intended, I’ll only flag the erroneous rows with a new column (flag_parse_error) instead of manually correcting them.
7.1 Indicator for interrupted statemetns
The transcripts feature bracket terms (‘fortsetzend’) to highlight statements which were interrupted by, e.g. the Chamber’s president, and subsequently continued by the speaker. This information can be relevant, e.g. if one is interested in the length of statements and hence would take into consideration that one statement was split into multiple rows. With this in mind, I’ll add an additional column which highlights split statements.
Code
df_data %>%
filter(str_detect(speaker_prep, regex("\\(fortsetzend\\)"))) %>%
select(row_id, speaker_prep) %>%
slice_head(., n=5)# A tibble: 5 × 2
row_id speaker_prep
<int> <chr>
1 272 Abgeordneter Mag. Christian Kern (fortsetzend):
2 285 Abgeordneter Mag. Andreas Schieder (fortsetzend):
3 339 Abgeordneter Dr. Alfred J. Noll (fortsetzend):
4 341 Abgeordneter Dr. Alfred J. Noll (fortsetzend):
5 357 Abgeordneter Christian Lausch (fortsetzend): Code
df_data <- df_data %>%
mutate(continuing=str_detect(speaker_prep, regex("\\(fortsetzend\\)")))8 Result & Wrap-up
We now have our final result. The dataframe contains 28,855 rows. The table below displays only the first 200 characters of each statement. The complete file can be downloaded as a csv-file here.