pos <- position_jitter(width = 0.2, seed = 1) #define seed for positioning
plot_dot <- df %>%
mutate(label2 = paste(country, scales::percent(lower_women_rel_num / 100,
accuracy = .1))) %>%
mutate(label2 = case_when( #create label only for thos countries you want to highlight
indicator == "other" ~ "",
.default = as.character(label2))) %>%
ggplot(., aes(
x = .5,
y = lower_women_rel_num,
color = indicator,
label = label2,
group = country)) +
geom_point(
position = pos #same pos
) +
geom_rect(
xmin = 0.75,
xmax = Inf,
ymin = -Inf,
ymax = Inf,
color = "white",
fill = "white"
) +
geom_text_repel(
xlim = c(.75, 1.2),
position = pos, #same pos
fontface = "italic",
color = "grey30",
segment.color = "grey30",
hjust = 0
) +
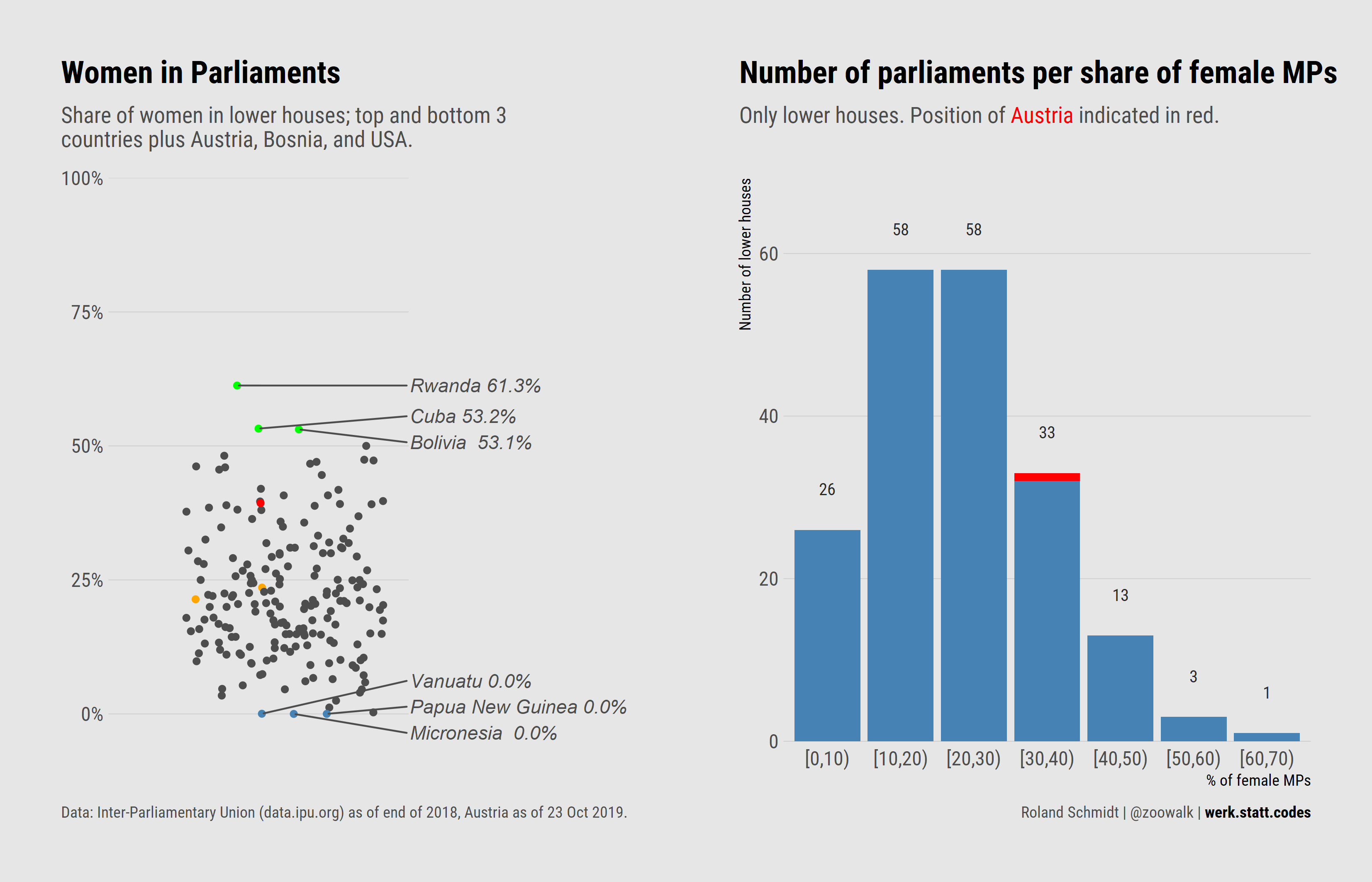
labs(
title = "Women in Parliaments",
subtitle = "Share of women in lower houses; top and bottom 3 \ncountries plus Austria, Bosnia, and USA.",
caption = c("Data: Inter-Parliamentary Union (data.ipu.org) as of end of 2018, Austria as of 23 Oct 2019.", "<br>Roland Schmidt | @zoowalk | <span style='color:black'>**werk.statt.codes**</span>")
) +
scale_y_continuous(
limits = c(-5, 100),
breaks = seq(0, 100, 25),
minor_breaks = NULL,
expand = expansion(mult = c(0.1, 0)),
labels = scales::percent_format(scale = 1, accuracy = 1)
) +
scale_x_continuous(
expand = expansion(mult = 0),
limits = c(0.15, 1.2)
) +
scale_color_manual(values = c(
"Austria" = "red",
"other" = "grey30",
"top" = "green",
"bottom" = "steelblue",
"select" = "orange"
)) +
hrbrthemes::theme_ipsum_rc() +
theme(
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
plot.subtitle = element_text(color = "grey30"),
legend.position = "none",
plot.title.position = "plot",
plot.caption.position = "plot",
plot.caption = element_markdown(color = "grey30"),
axis.title.y = element_blank(),
axis.text.x = element_blank())